TREVEX and VVI: an FPVI variant on AMD Zen 1–5
A black-box post-silicon fuzzer finds a new trigger for the 2021 floating-point value-injection primitive using output underflow rather than denormal inputs, and AMD folds it back into the existing advisory. The question is whether the 2021 mitigations, as actually deployed, still cover it.
The TREVEX methodology
On April 17, 2026, CISPA researchers (Weber, Thomas, Trampert, Zhang, Schwarz) published the TREVEX paper at IEEE S&P 2026 along with proof-of-concept code. TREVEX is a black-box post-silicon fuzzer for data-flow transient execution vulnerabilities. It runs the attacker and a victim process on sibling SMT threads, has both contexts execute the same or category-matched instructions using instruction shadowing, so arbitrary microarchitectural buffers get tainted without needing to know which ones matter, and flags test cases where the Flush+Reload cache footprint shows more than one transient value for an architecturally single-valued operation. It doesn't need RTL access or an ISA emulator, without leakage contracts.
A 25-hour campaign per chip across 20 microarchitectures from Intel, AMD, and Zhaoxin: 14,000 instructions × 100 test cases × 100 reps = 140M executions per chip which produced four concrete findings: FP-DSS (CVE-2025-54505) on Zen and Zen+, three Zero-at-ret instances on Intel, FPVI on Zhaoxin, and a new trigger for FPVI on AMD from Zen through Zen 5.
The FPVI finding
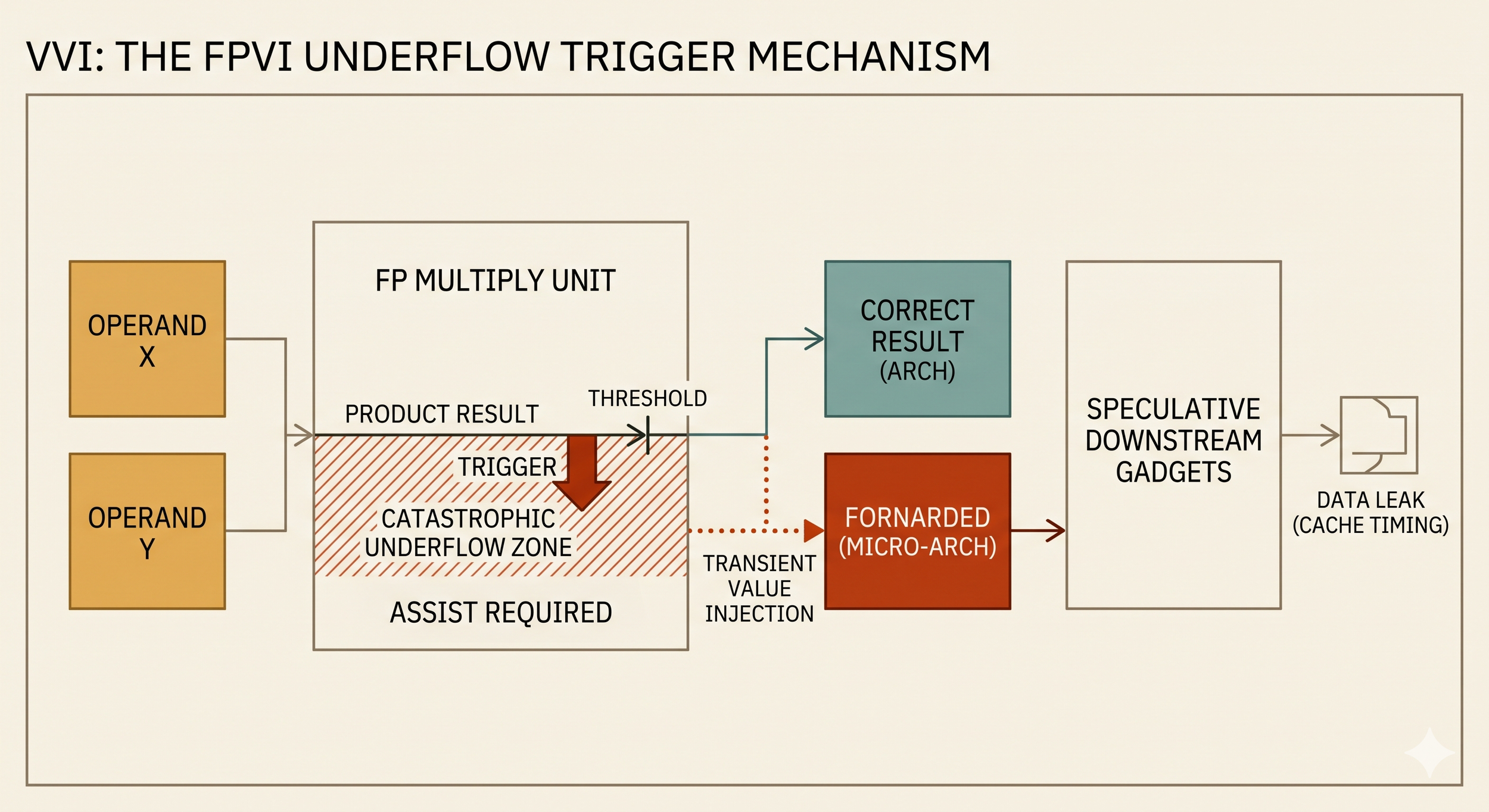
TREVEX observed that MULPD XMM1, XMM2 on AMD Zen 1 through Zen 5, demonstrated on Ryzen AI 9 HX 370, same uarch family as EPYC Turin, transiently forwards incorrect values without denormal inputs. The PoC operands are two non-denormal doubles with exponent field 0x081 (real exponent −894, values near 10−269); their product underflows catastrophically and cannot be produced on the fast path, forcing a microcode assist. During the assist's transient window, MULPD forwards a non-zero value to the output register instead of the architecturally correct zero.
The authors label this VVI (Vector Value Injection) in the PoC README. Disclosure to AMD, embargo extension granted, public release today. PoC at github.com/cispa/trevex, path /pocs/amd-fpvi-variant.
How VVI leaks data
The leak
Modern CPUs execute instructions optimistically. When a floating-point operation hits an unusual case, like a result so small it can't be represented as a normal number, and the fast path can't finish it. It pauses, calls in a microcode helper to produce the correct answer, throws away whatever it was doing on the fast path, and restarts with the right result. This cleanup is called a machine clear.
The bug is in what happens before the cleanup. On AMD Zen 1 through 5, when MULPD multiplies two numbers whose product is too small to represent (underflows catastrophically), the CPU forwards a wrong value to dependent instructions for a short window — dozens of cycles — before the machine clear fires and corrects course. Those dependent instructions run speculatively on the wrong value, then get squashed. Their architectural effects are thrown away, but their side effects on the cache are not.
The architectural result of the multiply was zero, like the math says. The microarchitectural side effect encoded the wrong value.
The pattern: attacker arranges for a victim to compute a multiply whose product underflows; the CPU transiently forwards garbage; instructions downstream of that multiply touch memory based on the garbage; those memory accesses leave a trace in the cache; the attacker measures which cache lines got warm and reads back the garbage byte by byte.
The exploit pattern
To turn the leak into something useful, the attacker needs three things arranged in the victim's code:
- A path to an underflowing multiply on attacker-influenced operands. Usually a JIT scenario: the attacker supplies JavaScript or WebAssembly, the JIT compiles it to a vector multiply, and the attacker picks operands that guarantee catastrophic underflow. In a managed runtime the attacker has full control over what gets multiplied.
- Downstream code that uses the multiply's result to index memory, or treats it as a pointer. In JavaScript engines that use NaN-boxing, this comes for free: the engine represents objects, strings, and doubles in a shared 64-bit slot using specific high-bit patterns to discriminate types. A transient wrong FP result whose high bits happen to look like a pointer gets consumed by later code as if it were a real pointer. The engine follows it, reads from that attacker-chosen address, and the read lands in the cache.
- A way to observe cache state after the transient window collapses. Flush+Reload is the standard technique: the attacker pre-flushes an array of 256 cache lines, one per possible byte value. After the victim runs, the attacker times reads to each line. The line that loads fastest corresponds to the transient byte the victim leaked.
The original Firefox case
In the 2021 FPVI exploit on SpiderMonkey, the attacker-supplied JavaScript computed something like x / y where both operands were chosen so the division produced a denormal result. The architectural answer was something boring like negative infinity. The transient answer was a bit pattern chosen to look like a NaN-boxed string pointer — specifically 0xfffb0deadbeef000, where 0xdeadbeef000 is the attacker's target address. Subsequent JavaScript code read .length off that "string," which made the engine dereference the transient pointer, which loaded the target address into the cache, which let the attacker read it back through the cache timing side channel. Architecturally none of this happened; microarchitecturally the attacker got arbitrary memory reads from the Firefox renderer.
How VVI changes the recipe
The new variant, VVI, widens the operand conditions that trigger the leak. The 2021 work framed FPVI as a denormal-input problem: you needed to feed the FPU a subnormal number for the assist to fire. VVI shows that underflowing outputs from normal inputs also trigger the assist. The PoC uses MULPD on two very small normal doubles whose product is too tiny to represent. Same transient window, same encoding primitive, different trigger.
Mitigations keyed to detecting denormal inputs don't fire, because VVI has no denormal inputs. Mitigations that set FTZ+DAZ to disable denormals entirely still work, because they eliminate the assist regardless of what caused it. Mitigations that mask FP results after the fact (the CMOVcc pattern Intel recommended and Mozilla shipped) still work for the NaN-boxing exploit class, because they care about the output bit pattern, not the trigger.
The practical structure of an exploit against VVI-vulnerable software looks the same as the 2021 Firefox attack: attacker-controlled operands, attacker-chosen transient bit pattern, downstream NaN-boxing-or-equivalent reinterpretation, Flush+Reload readout. The only thing that changes is how the operands are chosen — normal small numbers whose product underflows, rather than denormal operands directly.
Why the attack surface isn't everywhere
Catastrophic underflow is not a normal thing to happen in code. Compilers don't emit it, production workloads don't drift into it, real numerical code operates many orders of magnitude above where VVI triggers. The bug is only reachable when the attacker can choose the operands, which essentially means JIT compilation of attacker-supplied code, or a very narrow class of server-side handlers that accept arbitrary floats and multiply them without validation. This is why the realistic exposure concentrates on JavaScript engines and Wasm runtimes — not on HPC kernels, ML inference, graphics pipelines, or audio processing. The latter set operates on numbers that never underflow, and typically sets FTZ+DAZ anyway for performance.
Responses and mitigations
AMD's response is AMD-SB-7050, published the same day. Classified Informational, Potential Impact N/A, Severity N/A, no new CVE, two substantive sentences:
AMD believes that their FPVI variant falls within the existing scope of CVE-2021-26314 (FPVI) as existing descriptions of FPVI do not specifically require denormal inputs. Additionally, AMD believes that existing mitigation guidance for FPVI remains valid.
Redirects to AMD-SB-1003 from 2021.
What AMD's response is accurate about
The 2021 AMD-SB-1003 text and CVE-2021-26314 description describe FPVI as transient forwarding of incorrect results when an FP operation requires a microcode assist, without stipulating that the assist has to be triggered by denormal inputs specifically. The underflow-driven assist in VVI fits that abstract description. The 2021 FPVI mitigation recommendation of setting Flush To Zero and Denormals Are Zero (FTZ+DAZ in MXCSR) also covers VVI: FTZ flushes the underflowed result to zero before the transient window opens, short-circuiting the bug. The PoC README confirms FTZ+DAZ together stops the leak. Software that adopted the 2021 guidance properly is not exposed.
What AMD's response elides
The 2021 disclosure paper (Ragab et al., "Rage Against the Machine Clear," USENIX Security 2021) framed FPVI's trigger specifically as denormal/subnormal inputs, gave denormal-input examples throughout, and the ecosystem of downstream mitigations built against that framing. Intel's INTEL-SA-00516 guidance and CMOVcc-based masking pattern targets denormal-produced NaN results. Mozilla's Firefox fix (CVE-2021-29955) masks NaNs specifically from operations that can yield denormal outputs. Compiler-inserted lfence passes in some toolchains target denormal-producing ops. Any mitigation that scoped itself to input-denormal detection instead of adopting the broader FTZ+DAZ hardening will not cover VVI, because the trigger is underflow on the output side. AMD's framing treats the 2021 guidance as if it were uniformly implemented at the FTZ+DAZ level, when in practice many mitigations were implemented at the input-denormal-detection level.
The practical change
The FPVI primitive is unchanged in capability (attacker causes a transient wrong FP value to flow into victim execution; downstream gadgets turn that into disclosure or injection). The trigger condition expanded from "denormal input forces assist" to "any assist-requiring FP condition, including output underflow." Mitigations implemented as blanket FTZ+DAZ or blanket serialization still cover the bug. Mitigations implemented as denormal-input guards do not.
AMD's "existing mitigation guidance remains valid" is accurate for the guidance as written (the 2021 text recommended FTZ+DAZ) and misleading for the deployment reality, because many vendors implemented narrower mitigations tied to the denormal framing everyone used at the time. This is a code review question per affected component: does the deployed mitigation actually set FTZ+DAZ at the MXCSR level, or does it check input operands for denormal status? The former is covered. The latter is not. The most exposed environments are those that cannot set FTZ+DAZ because they require strict IEEE-754 semantics for untrusted code, which are primarily browser JavaScript engines and comparable managed runtimes.
AMD's informational classification is defensible. The PoC triggers on MULPD with operands (exponent −894) whose product underflows catastrophically, which requires a microcode assist — structurally the same assist-driven transient window the 2021 FPVI advisory describes, just reached via output underflow rather than input denormals. The 2021 mitigation recommendation (FTZ+DAZ) covers this case; the PoC README confirms FTZ+DAZ together stops the leak, though DAZ alone does not. Software that adopted the 2021 FPVI guidance properly is not exposed.
The genuine concern narrows to environments that cannot set FTZ+DAZ because they require strict IEEE-754 semantics — primarily browser JITs (V8, SpiderMonkey, JSC) and any managed runtime exposing IEEE semantics to untrusted code. For those, the 2021 mitigations targeted denormal-producing operations specifically; whether they also fire on underflow-producing ops is a code-review question per engine, not an assumed yes. Teams in that category should run the PoC against their JIT output before concluding the 2021 work covers them. Teams shipping FP-using enclave code, HPC kernels, or GPU driver paths that already enable FTZ+DAZ have no action to take beyond confirming those bits are actually set in the deployed configuration.
2021 FPVI mitigation landscape — per-component exposure
Mozilla Firefox / SpiderMonkey
Primary path covered · residual gadgets openCVE-2021-29955. The VUSec 2021 disclosure demonstrated an end-to-end exploit using NaN-boxing type confusion: a transient division result with exponent field indicating a tagged pointer value was consumed by downstream gadgets as a string pointer, enabling arbitrary memory read.
Mozilla explicitly rejected FTZ+DAZ as a "nuclear option" because it would break IEEE-754 semantics for JavaScript and WebAssembly, and could affect C++ code reached via DOM calls. The shipped mitigation (Firefox 87) places CMP+CMOV at the double-to-Value boxing step (LBox / LBoxFloatingPoint in WarpMonkey), enforcing the NaN-boxing invariant. Any transient FP result that violates the invariant is masked before it can be consumed as a tagged pointer.
The mitigation is result-based and structurally trigger-agnostic for the NaN-boxing exploitation path. Residual gadgets that use transient FP values as array indices, branch targets, or other non-type-confusion primitives are not ruled out.
V8 / Chrome / Edge / Node.js
Structurally less exposedV8 uses low-bit pointer tagging, not NaN-boxing. From v8/src/objects/tagged.h: small integers (Smi) have tag = 0 in LSB, 31-bit payload (32-bit payload on 64-bit with appropriate shifting); strong pointers tag = 01 in low two bits; weak pointers tag = 11 in low two bits. Doubles are either heap-allocated as HeapNumber objects (referenced by tagged pointer) or stored raw in PACKED_DOUBLE_ELEMENTS arrays. Type discrimination happens at the Map/ElementsKind level, not via bit-pattern aliasing with pointer representations.
The 2021 FPVI primitive, which is a transient FP bit pattern usable directly as a tagged pointer via NaN-boxing, and does not apply architecturally. The residual transient-execution attack surface is the PACKED_DOUBLE_ELEMENTS ↔ PACKED_ELEMENTS type confusion path, but all published exploits of that class (CVE-2020-16009, CVE-2021-30632, CVE-2025-2135) rely on architectural JIT compiler bugs to bypass Map checks rather than transient execution. Exploiting VVI against V8 would require constructing a gadget that achieves type confusion transiently through an FP assist, which has not been publicly demonstrated.
Chromium's cross-origin defense against transient-execution attacks is Site Isolation. In-process mitigations include bounds-check masking in TurboFan and W^X JIT code. No public commit, bug, or documentation in V8 or Chromium references FPVI, CVE-2021-0086, or CVE-2021-26314 specifically. The 2021 VUSec disclosure was concurrently reported to Chromium; the public outcome is not documented, though the likely position is that Site Isolation covers the cross-origin threat model and NaN-boxing-specific mitigations are not needed.
JavaScriptCore / Safari / WebKit
Same class as pre-mitigation SpiderMonkeyJavaScriptCore uses NaN-boxing, pointer-favoring variant. Doubles are offset by 1<<49 (originally 1<<48) to distinguish them from pointer-range bit patterns. Pointers occupy the low range with high bits cleared; integers occupy a reserved high-bit pattern.
This is architecturally the same exposure class as pre-mitigation SpiderMonkey: a transient FP result with high bits in the pointer-like range can be consumed directly as a tagged pointer. The 2021 VUSec disclosure was shared with WebKit, but no public FPVI-specific mitigation is documented in WebKit source, WebKit security advisories, or the WebKit blog.
Mitigation status not publicly documented; source examination finds no mitigations. However AMD is not really used for this software.
HPC · ML · media · graphics · GPU dispatch host code
Covered by default configurationThese workloads set FTZ+DAZ by default for performance reasons. Denormal handling is slow (microcode assist, 100+ cycles), and the numerical impact of flushing denormals is negligible for most applications. glibc's crtfastmath.o, -ffast-math, and equivalent compiler flags set the bits at program startup. Math libraries set them locally around compute kernels.
Standalone WebAssembly runtimes (Wasmtime, Wasmer, WasmEdge)
Primary path N/A · per-runtime reviewNo public FPVI mitigation documented. These runtimes follow the WebAssembly spec, which requires IEEE-754 semantics for f32 and f64 operations, so they cannot globally set FTZ+DAZ without violating the spec. They also do not use NaN-boxing for value representation — Wasm values are typed at the bytecode level and stored in typed slots — so the primary FPVI exploitation primitive does not apply.
Whether any Wasm runtime uses a CMOV-based FP result masking for security-sensitive operations requires source review per runtime.
Non-LVI-hardened privileged FP-using code in general
Exposed in principle · per-component auditFor any code that handles attacker-influenced FP operands and is reachable across a privilege boundary (syscall paths, hypervisor FP handling, enclave code not built with SGX SDK, kernel modules that process user-provided floats), exposure exists in principle. The gadget-hunting surface is narrower than the original 2021 FPVI framing suggested because the VVI trigger requires attacker-controlled operands whose product underflows catastrophically — production code rarely operates on numbers near 10−269 — but input validation that bounds magnitude at either end closes the gap.
Net position
The 2021 FPVI mitigation ecosystem, when implemented as Intel and AMD recommended, covers VVI. FTZ+DAZ stops the underflow-driven assist path. CMOVcc result masking catches transient values in the NaN-boxing-exploitable range. LVI hardening stops any transient execution after a load. All three are trigger-agnostic; none rely on the 2021 denormal-input framing.
AMD's SB-7050 position — that the VVI variant falls within existing CVE-2021-26314 scope because the 2021 descriptions did not specifically require denormal inputs — is defensible on the documentary evidence. The guidance as written does cover VVI.
The residual risk concentrates on components that implemented narrower mitigations than the guidance recommended, or that did not adopt any FPVI-specific mitigation at all. The most interesting unknowns are JavaScriptCore (same architectural exposure class as pre-mitigation SpiderMonkey, no public post-2021 mitigation documented) and any standalone Wasm runtime or managed runtime that exposes IEEE-754 FP semantics to untrusted code without a corresponding result-based or serialization-based hardening pass.
· · ·